Недавно начались некоторые опыты с морфологией, чтобы их произвести и обкатать некоторые алгоритмы, пришлось воспользоваться словарем от OpenCorpora. В исходном виде табличка со словарем включает около 405 тысяч строк, в каждой из них информация по формам слова, его лемме, род, время, падеж, одушевленное или нет, всё это занимает около 489 мегабайт.
Мне понадобилось вытаскивать по конкретному слову его данные, для этого составил табличку такого типа
| id | lemma_id | word | gram | gram_descr |
|---|---|---|---|---|
| 1 | 1 | клавиатура | ... | ... |
В поле gram прописываются некие теги по данному слову, а gram_descr - описание этих тегов (это пока для тестирования и анализа первая штука).
Например вот так
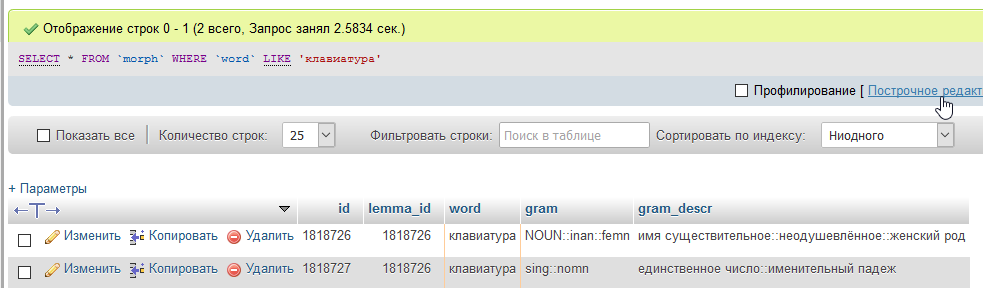
Можно прибегнуть к системам полнотекстового поиска, может так и сделаю, но меня первым делом смущает работа по http некоторых таких систем, если надо будет 1000 запросов в секунду кидать, ну я их еще проверю, еще планирую потестировать всякие MongoDB.
У меня получилась таблица с более чем 2.2 миллионов строк, попробуем поискать по ней слово "клавиатура", для того, чтобы гарантированно без всяких кешей получать время запроса, будем добавлять после SELECT параметр SQL_NO_CACHE. Выполняю несколько раз и получаю минимальный результат...
Итак, поехали, попробуем получить клавиатура... Как видим, 2.4 сек, иногда до 3.4 доходило, это очень ужасно.

Теперь попробуем по точному совпадению key=>val. Ситуация особо не меняется, странно, но даже дольше выполняется, несколько раз перезапускал и оно только вот так, 2.5 сек, такой результат еще более ужасный.

Теперь попробуем такую мощную штуку, как полнотекстовый поиск, для этого нужно добавить полнотекстовый индекс к полю word...
ALTER TABLE `morph` ADD FULLTEXT(`word`);К слову, у меня этот индекс был уже изначально на момент тестирования, выполняем запрос
SELECT SQL_NO_CACHE * FROM `morph` WHERE MATCH(word) AGAINST('клавиатура')И о чудо, 0.0004 сек, вот такой результат более чем приличный

Но если мы будем искать всякие местоимения, частицы, союзы и другое в стиле - "за", "с", "а", "мы", "я"... И еще такие слова как ёж, уж, Ра.
В конфигурации my.cnf есть такой параметр, если нет, то по умолчанию стоит 4, все что короче - игнорнируется.
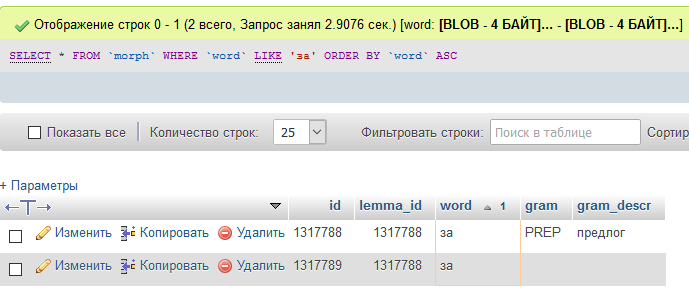
ft_min_word_len = 4Тут видно, что предлог "за" есть в таблице..
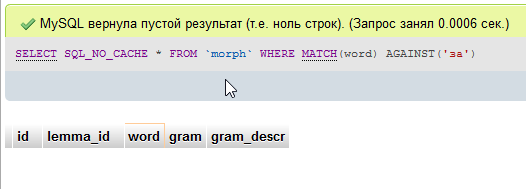
Но так не сможет его найти, т.к. есть ограничение
Давайте попробуем снять это ограничение, пропишем в конфиг [mysqld]
ft_min_word_len = 1Ничего не выходит, наверно нельзя по одной или двум буквам искать, значит нам это не совсем подходит... Но мы можем например выделить все слова до 3х символов в отдельную таблицу и там будет искать их быстро обычными методами...
В любом случае, этот метод будет достаточно хорош для поиска по текстам на сайте, например по описаниям товаров, если особенно на обычном хостинге, где нет Sphinx, ElasticSearch и другого такого.
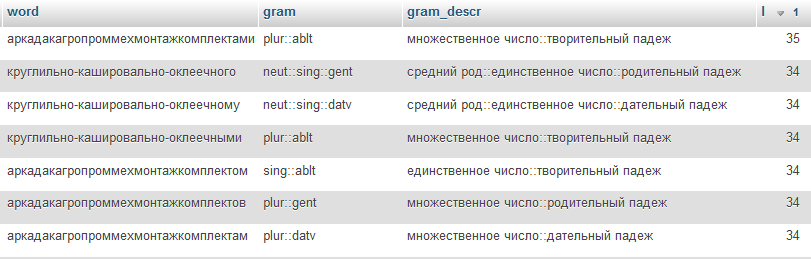
Определим сколько у нас максимальное по длине слово
SELECT SQL_NO_CACHE *, char_length(word) as `l` FROM `morph` ORDER BY `l` DESCПолучим 35, слова такие конечно редкие, но мы должны предусмотреть максимальную базу данных
Попробуем тип поля сделать не text, а varchar 50, а потом поискать стандартным способом через like, ничего не поменялось...
Попробуем сравнение изменить на utf8_bin
С Like ситуация не поменялась, с полным WHERE тоже, но теперь появилась возможность сделать простой индекс не полнотекстовый для поля word
ALTER TABLE `morph` ADD INDEX(`word`);После добавления индекса к полю, у меня стало искать за доли секунды
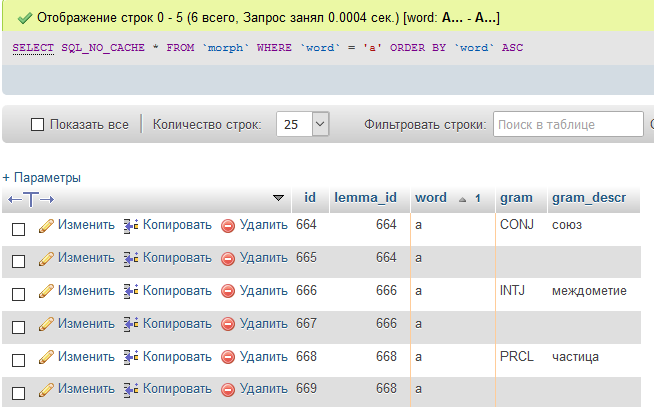
При таком раскладе, скорость получения данных по словам будет 2500 слов в секунду, не плохо... Правда сравнение utf8_bin накладывает некоторые ограничения, например нет регистронезависимого поиска, нужно при выборке и хранении понижать регистр, хотя тут вроде итак всё в нижнем регистре.
Попробуем поменять сравнение в поле на utf8_unicode_ci, и снова перестроить индекс может там не сильно будет потеря, да, MariaDB вполне справляется, то что пишут на форумах про ускорение в сравнении bin наверно уже устарело.
Теперь попробую еще одну идею, добавить в таблицу поле length и записать в него длину, сделаем его INT(2), ну максимум у нас все равно слово может быть 50 букв, хотя это там даже не слово, а какие то длинные названия. И сделаем поле индексированным.
Сделаем такой запрос для его заполнения
UPDATE morph
SET morph.length = CHAR_length(morph.word)
А теперь попробуем поискать вот так
SELECT SQL_NO_CACHE *
FROM(SELECT * FROM morph WHERE length=1) as t
WHERE word='б'Нет, это не дало результата должного, уже нет такого критичного времени, которое может оптимизироваться, но идея заключалась в том, чтобы выбрать по индексированному полю с длиной строки, а потом из этого уже по слову искать.
Выводы: если нужна выборка по текстовому полю, например ЧПУ страницы сайта, то надо использовать поле varchar фиксированного размера и добавлять к нему индекс, как видите, с миллионами записей справляется идеально... Если же нужен поиск по текстам описаний (text) с вхождением слов, то лучше использовать полнотекстовый поиск, он достаточно быстрый.